
Building FINCPA: Turning Financial Law into Compliance Data
FINCPA was built as a hackathon prototype for the JB Financial Group Fin AI Challenge. The product idea was simple to explain but tricky to implement:
Can we help review financial advertising without letting a language model become the legal judge?
That question matters because financial compliance is not only a text-generation problem. If an AI system says “this ad looks fine,” a reviewer needs to know why. Which rule was checked? Which legal clause supports it? Which disclosure was missing? Which field in the ad caused the finding? Could the decision be reproduced tomorrow?
The architecture we proposed answers those questions with a compiler-style workflow. The law is converted into structured compliance data first. The runtime input is converted into a structured representation second. A deterministic engine compares the two. Only after that does the LLM help with explanation and conservative rewrite suggestions.
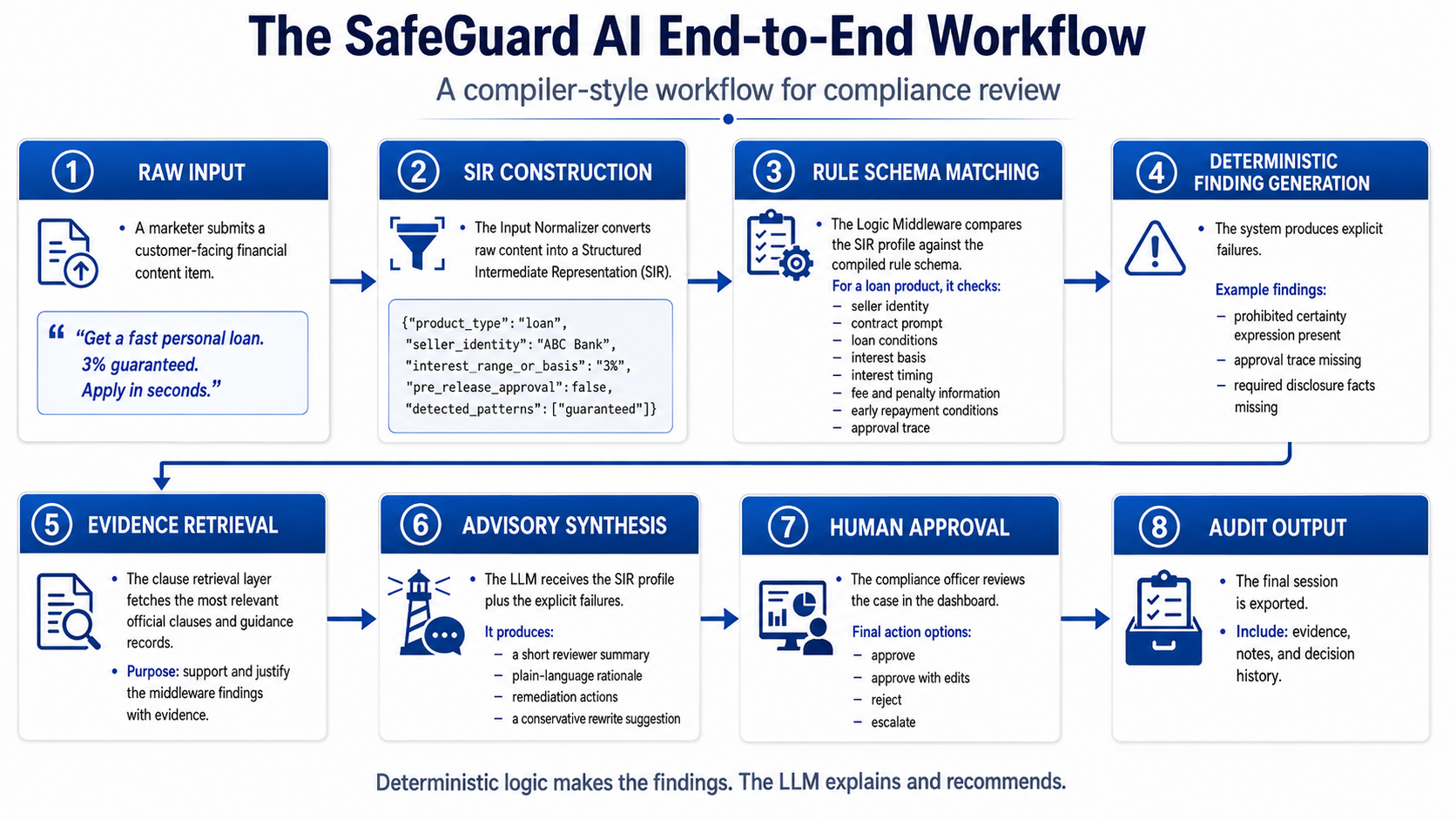
The Main Design Choice
A weaker design would be:
user ad → LLM → compliance decision
That is easy to demo, but hard to trust. It makes the model responsible for interpreting law, applying rules, and explaining itself in one step.
FINCPA uses a different flow:
law → structured rules
ad → structured facts
rules + facts → deterministic finding
finding + evidence → LLM explanation
reviewer → final approval
This separation is the whole project. The LLM is useful, but it is not the first judge. The system first asks: what can we prove from structured legal data and structured input fields?
Scope: One Legal Chapter First
The prototype focuses on Chapter 4 of the Financial Consumer Protection Act, especially customer-facing conduct and financial-product advertising. Instead of trying to cover every regulation in Korea, the project builds one defensible legal core:
- one official law PDF,
- one chapter scope,
- clause-level parsing,
- obligation decomposition,
- rule candidate compilation,
- MVP rule freeze,
- runtime review examples.
That may sound narrow, but narrow is good for a hackathon prototype. A smaller scope lets the team show traceability. Every rule can point back to source text.
Building the Legal Dataset
The first layer is deterministic parsing. The source PDF is trimmed to the Chapter 4 range, then segmented into article and paragraph-level records. The current parse produces 60 clause records across the Chapter 4 scope.
In abstract form, we can think of the source law as a sequence of clauses:
\[C = \{c_1, c_2, \ldots, c_n\}\]where each clause record contains metadata such as article reference, paragraph marker, source text, normalized text, and source path.
For FINCPA:
\[n = 60\]The important point is that this layer does not ask an LLM to make a compliance judgment. It only creates clean legal units.
From Clauses to Obligations
Legal clauses are often dense. One paragraph can contain several operational requirements, exceptions, or prohibited behaviors. So the next step decomposes clauses into smaller obligation units.
We can describe that as a mapping:
\[g(c_i) = \{o_{i1}, o_{i2}, \ldots, o_{im}\}\]where each $o_{ij}$ is an obligation or rule-relevant unit derived from clause $c_i$.
In the current FINCPA pipeline:
\[|O| = 109\]This is where the legal text starts becoming useful for computation. Instead of treating the law as paragraphs, the system treats it as operational units: required disclosure, prohibited expression, required process, required record, or required response.
Compiling Candidate Rules
Once obligations exist, the system can compile rule candidates. Each candidate connects a legal obligation to things the runtime system can actually inspect.
A useful rule row needs at least:
- legal basis,
- product scope,
- channel scope,
- rule family,
- logic type,
- detection target,
- candidate SIR fields,
- evaluation hint.
At this point the project has 109 Layer 3 rule/SIR candidates.
But candidates are not enough. A product demo needs a frozen MVP. So Layer 4 applies a deterministic selection rule:
\[R_{mvp} = \{r_k \in R_{candidate} \mid ready\_for\_v1(r_k)=yes\}\]That produces:
\[|R_{mvp}| = 76\]and a frozen SIR schema with:
\[|F_{sir}| = 29\]This is the moment the project becomes a real data system. The rule pack is no longer just notes about the law. It is a machine-readable compliance artifact.
What Is SIR?
SIR means Structured Intermediate Representation. It is the normalized form of the user input.
A financial ad is messy text:
Fast personal loan. 3% guaranteed. Apply in seconds.
The runtime needs something more explicit:
{
"product_type": "loan",
"seller_identity": "present",
"loan_conditions": "present",
"loan_rate_basis": "not_evidenced",
"loan_interest_timing": "not_evidenced",
"prohibited_claim_signal": "present"
}
SIR is the bridge between human language and legal rules. It lets the engine ask precise questions:
- Is the product type known?
- Is the seller identified?
- Are required cost disclosures present?
- Is a prohibited certainty phrase detected?
- Is the required warning missing?
Deterministic Review
Each rule can be evaluated against the SIR fields. A simple required-presence rule can be written as:
\[fail(r_k, x) = \begin{cases} 1, & \text{if required field } f_k \text{ is not evidenced in } x \\ 0, & \text{otherwise} \end{cases}\]For prohibited-presence rules:
\[fail(r_k, x) = \begin{cases} 1, & \text{if prohibited signal } p_k \text{ is present in } x \\ 0, & \text{otherwise} \end{cases}\]The final decision can be simplified as:
\[d(x) = \begin{cases} \text{non-compliant}, & \sum_k fail(r_k, x) > 0 \\ \text{review}, & \sum_k uncertain(r_k, x) > 0 \\ \text{compliant}, & \text{otherwise} \end{cases}\]The actual system keeps more detail than this, including applicable rule counts, missing SIR fields, triggered citations, failed rule IDs, escalation flags, and reviewer packets.
Example: Guaranteed Investment Return
One runtime example tests an investment ad with a guaranteed-return signal. The engine marks the case as non-compliant and escalates it. It triggers rules connected to advertising obligations, including missing investment-warning evidence and a prohibited claim signal.
The useful part is not only the label. The useful part is the evidence trail:
- final decision:
non_compliant - escalation:
true - applicable rules:
3 - failed rules:
2 - missing SIR field:
investment_warning - triggered citations: Financial Consumer Protection Act Article 22 paragraph 3 and 4
This is what makes the system reviewable. A compliance officer does not have to accept a black-box sentence. They can inspect which field was missing, which rule failed, and which legal citation was attached.
Why Dashboards Matter
The repository includes two dashboard views.
The first dashboard is for the legal compilation pipeline. It shows how a clause moves through parsing, Layer 1 metadata, Layer 2 obligation decomposition, Layer 3 rule/SIR candidate design, and the Layer 4 freeze.
The second dashboard is for runtime review. It shows a new input moving through:
- prompt/input,
- runtime schema,
- SIR extraction,
- active rules,
- triggered law,
- final result.
This was important for the hackathon because the project has many JSON and JSONL artifacts. A dashboard makes the pipeline explainable to judges, teammates, and future reviewers.
Where the LLM Fits
The LLM is still useful. It can turn a technical review result into language a human can act on:
- reviewer summary,
- plain-language rationale,
- remediation actions,
- conservative rewrite suggestion.
But the LLM receives the structured finding after the deterministic engine has already created it. That makes the system safer:
\[LLM\_input = \{original\_text, SIR, failed\_rules, citations, evidence\}\]The model explains the decision. It does not invent the legal basis.
Limitations
FINCPA is a prototype, not a production compliance system. The current scope focuses on Chapter 4 and does not yet include the full stack of presidential decrees, supervisory regulations, enforcement cases, and product-specific advertising guidance.
The SIR extractor is also an MVP. Real deployment would need better entity extraction, stronger Korean financial-language coverage, more robust OCR/document input, reviewer feedback loops, and ongoing legal updates.
Still, the prototype shows the right shape: legal data should be traceable, rules should be auditable, and LLMs should be placed where they help without becoming the hidden judge.
Conclusion
FINCPA is a data engineering story disguised as a compliance AI project.
The core work is not just building a dashboard or calling an API. The core work is turning law into structured data, turning ads into structured facts, comparing them deterministically, and packaging the result so a human reviewer can make the final decision with evidence.
That is the lesson I like most from this project: in high-stakes domains, good AI starts with good structure.
You can explore the code, dashboards, and artifacts here:
GitHub: rashiedomar/FinTech
Legal compilation dashboard
Runtime flow dashboard