
Tourist Taste Korean Food

This data story explores how people talk about Korean food online, using Reddit discussions as a public text dataset. The goal was not only to count popular dishes, but to turn messy community conversations into a readable view of taste, ingredients, cooking style, and food experience.
The project uses a full text analytics workflow: data collection, text cleaning, token preparation, frequency analysis, word cloud visualization, and LDA topic modeling.
Dataset
The dataset contains 500 public Reddit posts from r/KoreanFood. Each record combines post metadata and discussion text, including title, score, URL, timestamp, body text, comment count, flair, comments, and a combined full-text field.
After preprocessing, the project keeps both the original text and a cleaned token representation. The processed file includes 500 rows, with a median of 22 processed tokens per post and about 14,190 final filtered tokens used in the analysis notebook.
The most common flairs in the collected sample were Homemade, Soups and Jjigaes, questions, Kimchee, Noodle Foods/Guksu, and Street Eats. That mix matters because the story is not only about restaurant dishes; a lot of the conversation is home cooking, comfort food, and everyday food memory.
Workflow
The pipeline starts with Reddit collection, then prepares the text for analysis:
- Combine titles, body text, and comments into a single text field.
- Lowercase text and remove URLs, punctuation, numbers, and noisy symbols.
- Tokenize the cleaned text.
- Keep useful parts of speech, mainly nouns and adjectives.
- Lemmatize tokens and remove general plus food-analysis stopwords.
- Build frequency tables, a word cloud, and an LDA topic model.
This workflow turns unstructured discussion threads into a dataset that can be explored visually.
What People Talk About
The strongest terms are basic anchors of Korean food discussion: kimchi, rice, egg, sauce, spicy, noodle, chicken, soup, and bibimbap.
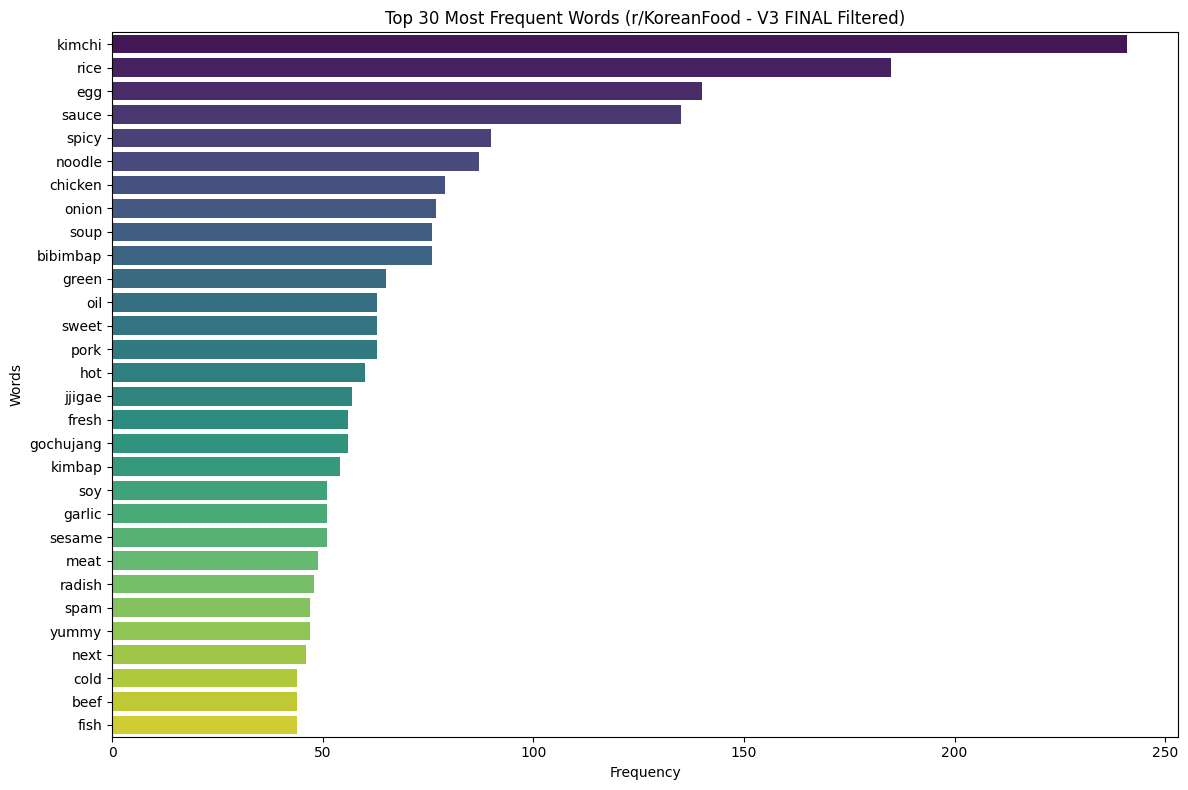
Kimchi is the central term in the sample, followed by rice and egg. This is useful because it shows the discussion is grounded in staple foods and everyday plates rather than only famous restaurant dishes. Sauce, spicy, soup, gochujang, garlic, and sesame point toward flavor systems. Bibimbap, jjigae, kimbap, bulgogi, banchan, and tofu show recognizable Korean dish categories.
Word Cloud
The word cloud gives a quick visual summary of the same pattern. Large terms such as kimchi, egg, rice, sauce, spicy, noodle, soup, and chicken dominate the conversation, while smaller terms fill in texture: banchan, gochujang, jjigae, kimbap, sesame, pork, fish, tofu, fresh, sweet, and hot.
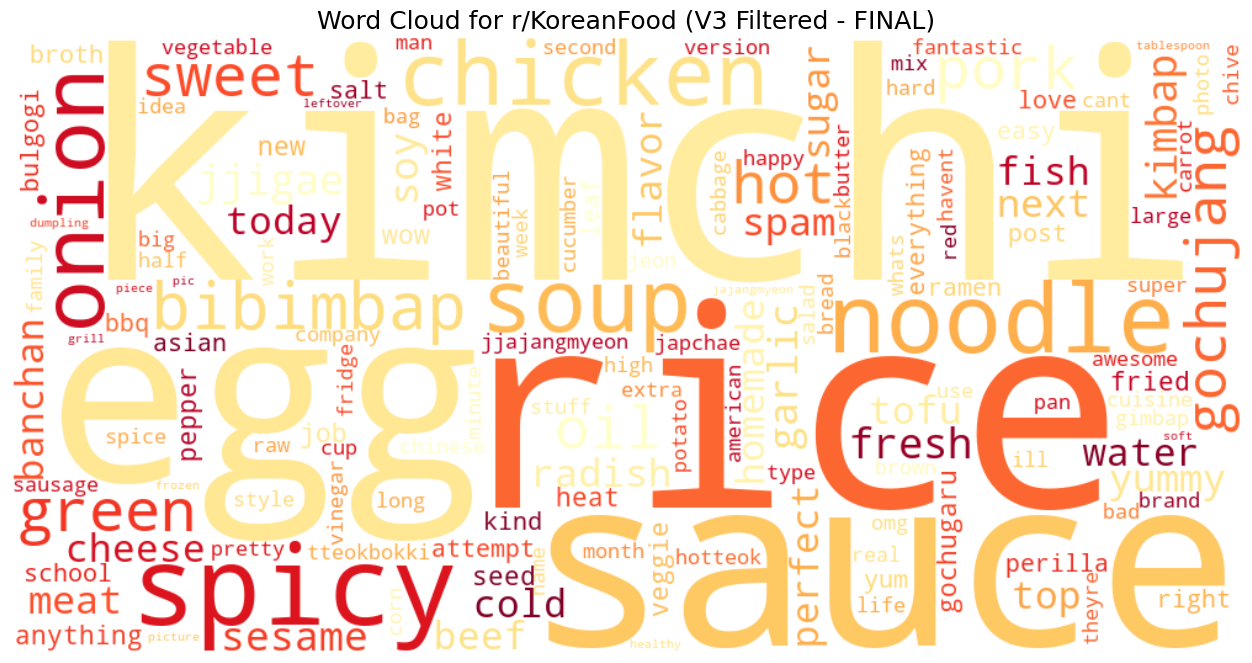
For a reader, this makes the dataset easier to scan. The visual language of the community is practical: ingredients, taste, heat, home cooking, and dish names appear together.
Topic Modeling
The LDA model was used to group the cleaned token data into themes. The interactive visualization separates the discussion into six topics, with the largest topic covering about 29.7% of the modeled corpus and the second about 21.5%.
The topic terms suggest several food-story clusters:
- Sauce, chicken, onion, sweet, cheese, soy, pork, and BBQ.
- Rice, kimchi, bibimbap, fresh, spicy, fried, egg, and pork.
- Noodle, soup, cold dishes, jjigae, tofu, seafood, and broth-like themes.
- Side-dish and ingredient language around banchan, sesame, garlic, cucumber, cabbage, and vegetables.
Open the interactive topic model here:
Takeaway
The analysis shows Korean food discussion as a blend of staple foods, comfort dishes, flavor intensity, and home-cooking culture. The most visible terms are not abstract opinions; they are concrete ingredients and dishes. That makes this dataset useful for a tourist-facing food story, because it reveals what people repeatedly notice, describe, cook, and recommend.
The project is also a compact example of an end-to-end data analysis workflow: collect public text, clean it, structure it, visualize it, model topics, and turn the results into an interpretable story.